On the Robustness of Self-Supervised Representations for Multi-view Object Classification
In this post, I’ll talk about a paper we recently published on the robustness of self-supervised representation with respective to viewpoint variation - one of the core tenants of any capable vision system. At this point, it is known that vision models pretrained using self-supervised objectives outperform standard supervised pretraining on a set of common, standard benchmark datasets such as ImageNet, CIFAR10, COCO, and Birdsnap. However, these datasets all serve to evaluate these models in a very narrow aspect - simple object classification performance.
Little work has been done to evaluate these models in a more granular way, and on more niche datasets. In this paper, we evaluate these models specifically with respect to multi-view recognition performance. We tackle this problem through two main approaches. Firstly, we synthetically vary viewpoint by approximating it with a homography of different strength. This allows us to have fine-grained control of the viewpoint, and serve as an initial way to benchmark supervised learning against self-supervised (SS) learning in this domain. Then, we evaluate the models on real-world, multi-view datasets.
An Empirical Measure of Robustness
We define an empirical measure of robustness to viewpoint variation in order to quantify and rank models during evaluation. Consider functions \(f : \mathcal{X} \rightarrow \mathbb{R}^n\) and \(g : \mathcal{X} \rightarrow \mathbb{R}^n\), and a sample space of images \(\mathcal{X}\). These are the supervised pretrained and SS pretrained models, respectively. We aim to analyse the efficacy and representational power of embeddings \(f(x), g(x) \in \mathbb{R}^n\) in terms of robustness to viewpoint variation. Essentially, we aim to analyse whether SS representations produced by \(g\) are more robust to those from \(f\). Mathematically, this can be formalised as follows. Consider a function \(V : \mathcal{X} \rightarrow \mathcal{X}\) that is tasked with altering an object’s viewpoint. Then, a function \(g\) is more robust to \(V\) than a function \(f\), if:
\[\mathbb{E}[L(f(x), f(v(x)))] \ge \mathbb{E}[L(g(x), g(V(x)))]\]for some loss function \(L\), and for all \(x \in \mathcal{X}\). This is the criterion we use to measure and compare models’ multi-view recognition performance, and implicitly, their viewpoint invariance.
Synthetic Viewpoint Variation Analysis
We alter viewpoint in a controlled environment by applying a homography to an image. We represent a homography as \(H_{\alpha} : \mathcal{X} \rightarrow \mathcal{X}\), where \(\alpha \in [0, 1]\) is the strength of the homography.
We also evaluate the potential bias of the models towards the black background induced from performing a homography on an image. We do this using (what we term) a bounded homography, whereby we crop the maximum-area inscribed axis-aligned rectangle from the resulting polygon. An example can be seen below:

The below table contains the results using linear evaluation on a host of common benchmark datasets:
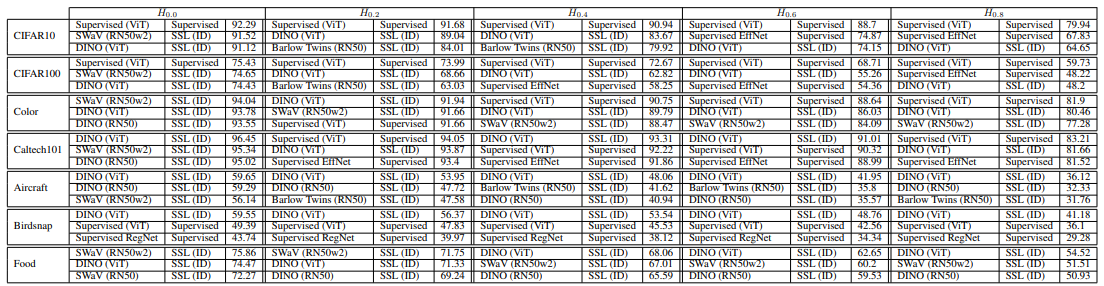
Interestingly, the supervised baselines perform best on the 2 most common small-scale benchmark datasets - CIFAR10 and CIFAR100. The rest of the datasets are dominated by SSL models. Next, we show a summary of results by synthetically varying viewpoint using homographies of strength 0.2, 0.4, 0.6, and 0.8.
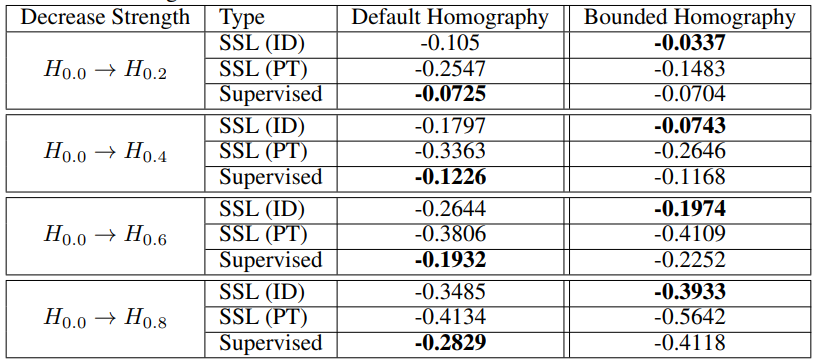
These results suggest that supervised models are more biased towards the black backgrounds induced in default homographies, and when accounted for using the bounded homography, SSL consistently performs best.
Multi-view Performance in the Wild
We evaluate these models in a real-world environment using a set of 5 inherently multi-view real-world datasets (see paper for details). Below if a table of the top-performing models overall for each of these:
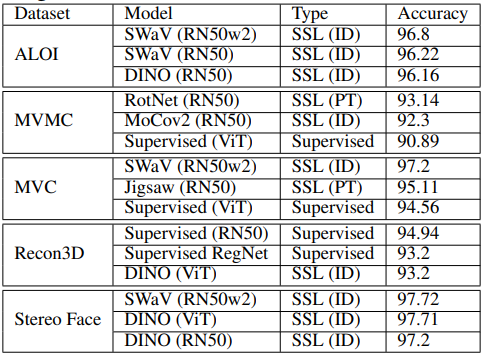
Once again, SS methods dominate - except for Recon3D. This is an expected results, since this dataset is the least like ImageNet (the dataset all evaluated models were pretrained on). It has been shown that SS models are less robust than supervised models when evaluated on datasets that contain data with a large distribution shift from ImageNet. Next, we show results for varying the amount of context a model requires to perform retrieval of the correct object (at a different viewpoint):
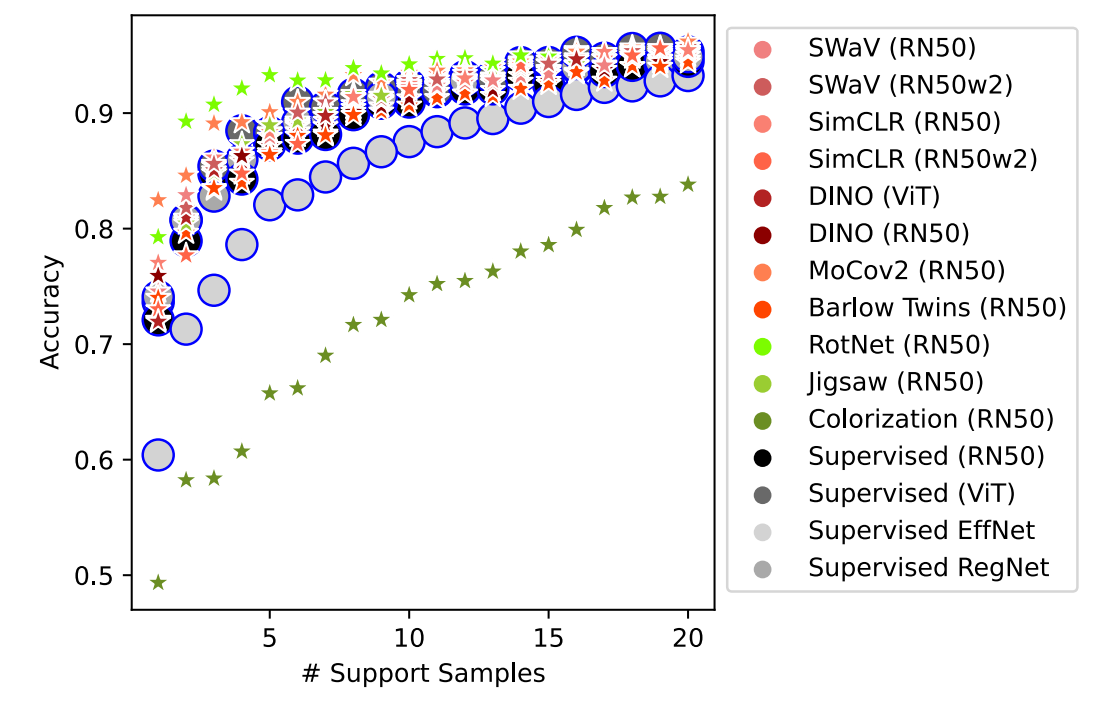
We see that with as few as one image per class, SS techniques outperform the supervised baselines significantly. We encourage you to see the paper for further experiments on evaluating models with respect to the amount of context needed to perform a particular multi-view task.
TL;DR
- Representations learned through SS techniques are shown, in multiple scenarios, to be more robust to viewpoint changes. This holds for both the synthetic, and real-world experiments.
- We show that with very little context (e.g. number of support samples, amount of training images, etc.), SSL consistently outperforms the supervised baselines in a real-world environment.
- We posit that SS representations encode information more pertinent to object parts (as a byproduct of the training objectives), which enables improved robustness to viewpoint.
- In our experiments, the instance discrimination class of SSL models outperforms the pretext task class of SSL models, but supervised models outperform the latter.
- ViT-based supervised and SS models show promise, and perform best in many experiments.