An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
As is commonly known at this point, transformers have transformed the field of NLP, and sequence modelling in general. However, computer vision has thus far remained dominated by the CNN. Its inductive biases result in unparalleled efficiency in terms of data and parameters for modelling data with a grid-like topology - most often images or video.
However, it is known that a vanilla MLP (under certain assumptions) is a universal approximator of continuous functions defined on compact subsets of \(\mathbb{R}^n\). Therefore, architectures without such strong inductive biases (such as the locality assumptions and convolution in CNNs) may work just as well for computer vision. Although previous attempts have been made to model images using non-CNN neural network architectures, none have enjoyed the widespread success and utility of the CNN and its derivatives. One of the major problems of applying transformers (or more broadly, self-attention) to images is the inherent dimensionality of image data. In vanilla self-attention, one would need every input to attend to every other input. With text data, this is more manageable than with images, since one would need to attend from every pixel to every other pixel in an image (in the vanilla formulation). This is computationally infeasible.
This post focuses on a paper that shows that competitive performance to state-of-the-art can be achieved using a transformer-like architecture, thereby (somewhat, as we will see) circumventing the strong inductive biases in CNNs. There are a few caveats to this claim, which will be elaborated upon below. The architecture proposed in this paper is known as vision transformer (ViT).
There have been previous attempts at trying to reduce the reliance of CNNs for computer vision architectures in preference for self-attention and transformer-based architectures (see this, this, and this). However, these previous attempts are notably more complex than the standard transformer, and thus cannot benefit from the vanilla formulation’s computational efficiency and scalability - which will see is essential for these non-CNN architectures to compete. Because of this, ViT aims to make as few modifications as possibile to ensure the maximum benefit in terms of scalability and efficiency from the standard transformer can be realised.
The architecture is fairly simple, and seems to be a natural way to model images using a transformer-like architecture (see below):
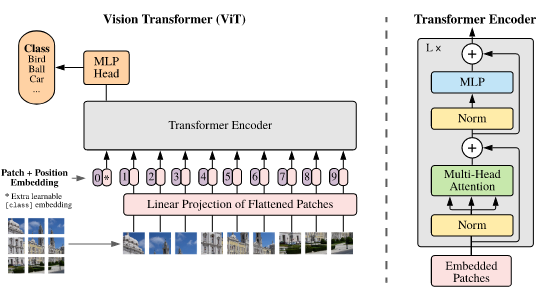
An image is broken up into patches, and each patch is flattened and projected into a latent space using a linear projection (using a projection matrix \(E\)). However, without additional information, the transformer would be processing the patches as a set instead of as sequence. This would make the result permutation invariant, which is not ideal in this case. To overcome this, the authors assign (much like in NLP applications of transformers) positional embeddings to each of the patch embeddings to give the transformer context of patch ordering.
After this point, it is a standard transformer model (i.e. the transformer encoder from the original transformer paper) that eventually maps to the class prediction. This is interesting as there is no convolution present in the architecture, thereby forgoing the strong inductive biases made by CNNs. The global approach to self-attention in ViT is a weaker prior than the strong locality assumption made when performing convolution. The only time priors based on the 2D structure of images is added into the modelling process of ViT is when higher resolution images are fed in. In this case, the effective sequence length is longer for the same patch size, at which point the positional embeddings may not be as meaningful as for shorter image patch sequences. Thus, 2D interpolation of the positional embeddings is performed, according to their location in the original image.
The results of ViT are interesting. Due to the lack of strong, but beneficial inductive biases of CNNs, the ViT does not perform well when the amount of data is not large enough. Only when the scale of the data is, frankly, ridiculous (300M images), does the ViT start outperforming ResNet-like architectures. At smaller scales, the ViT is not as competitive, but does take far fewer computational resources to train to achieve the same accuracy as the state-of-the-art CNNs.
Interestly, even without the manual injection of image-specific priors, the ViT model still learns surprising things during training. For example, the linear projection (to embed the patches into the initial latent space), learns filters that are surprisingly similar to those usually learned by CNNs (see below).

Overall, applying more general, scalable models to problems is often a good approach to take, and transformers are in many ways the most general neural network architectures we currently have that work (more so than vanilla MLPs). Their current utility for computer vision, even with ViT, is somewhat limited due to the computational resources required for training them at scale being infeasible for most people (as compared with CNNs). However, it is most definitely a promising step in the direction of converging on a unified architecture that can effectively model any modality of data (images, video, text, audio, etc.).